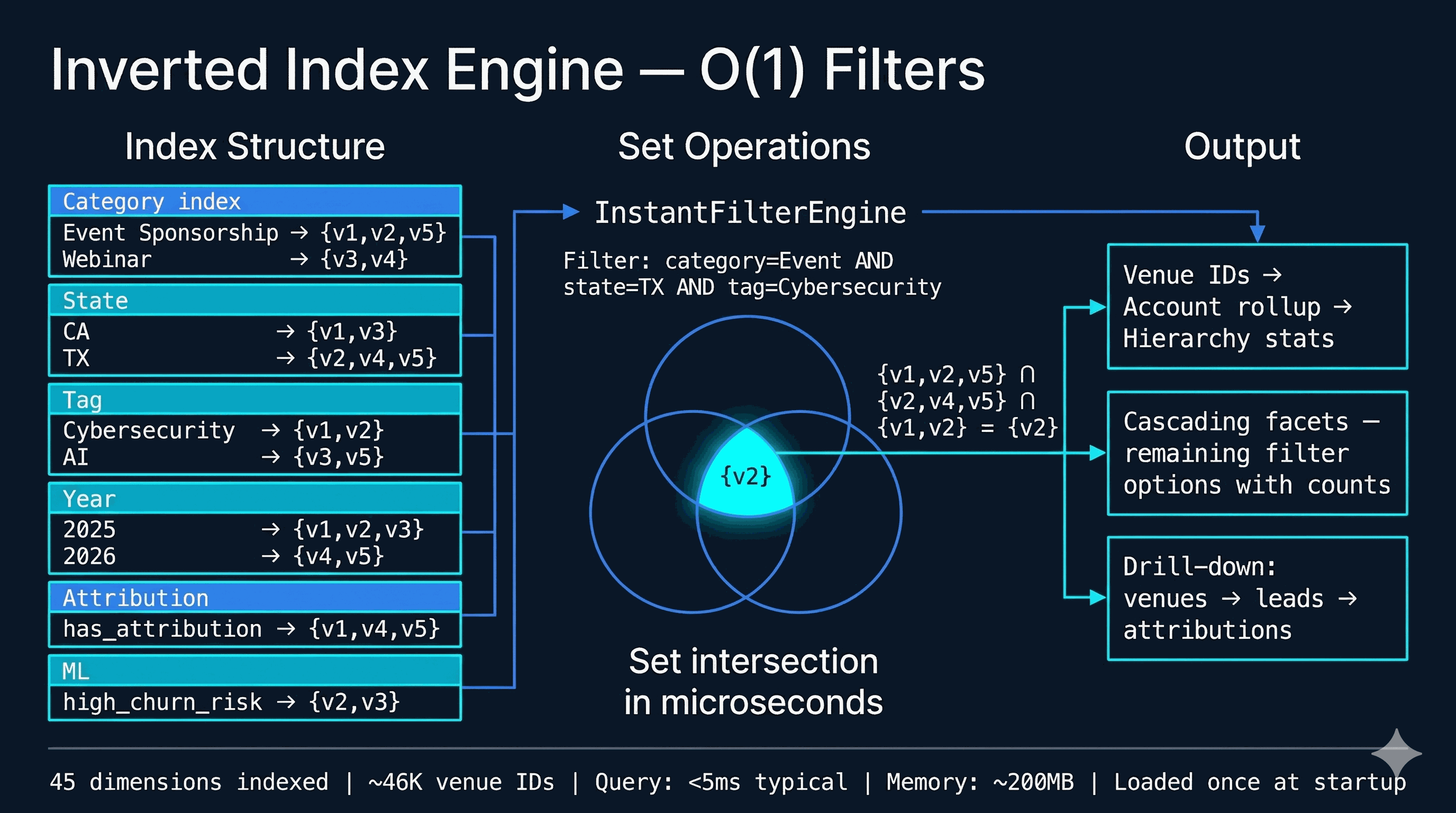
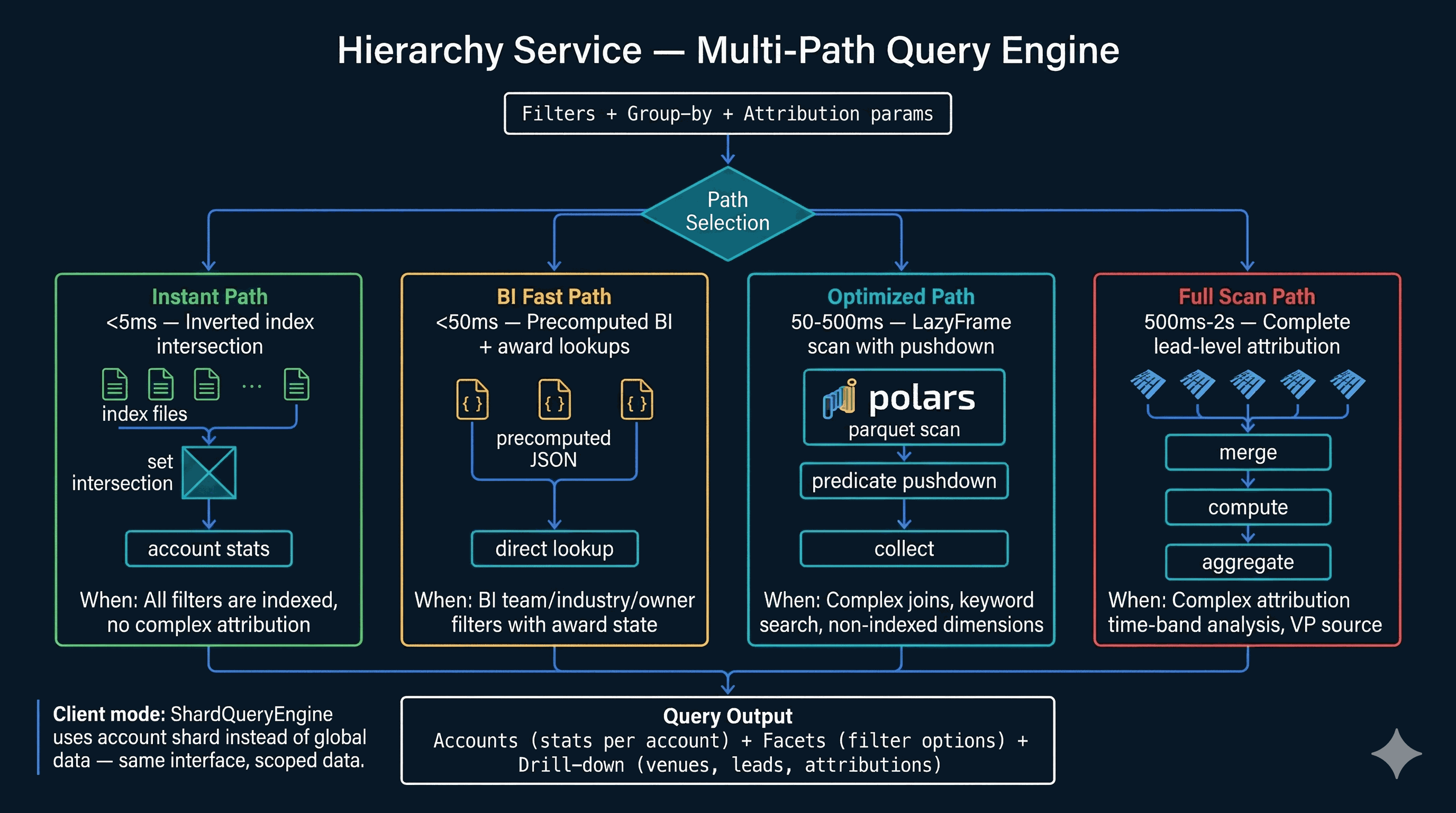
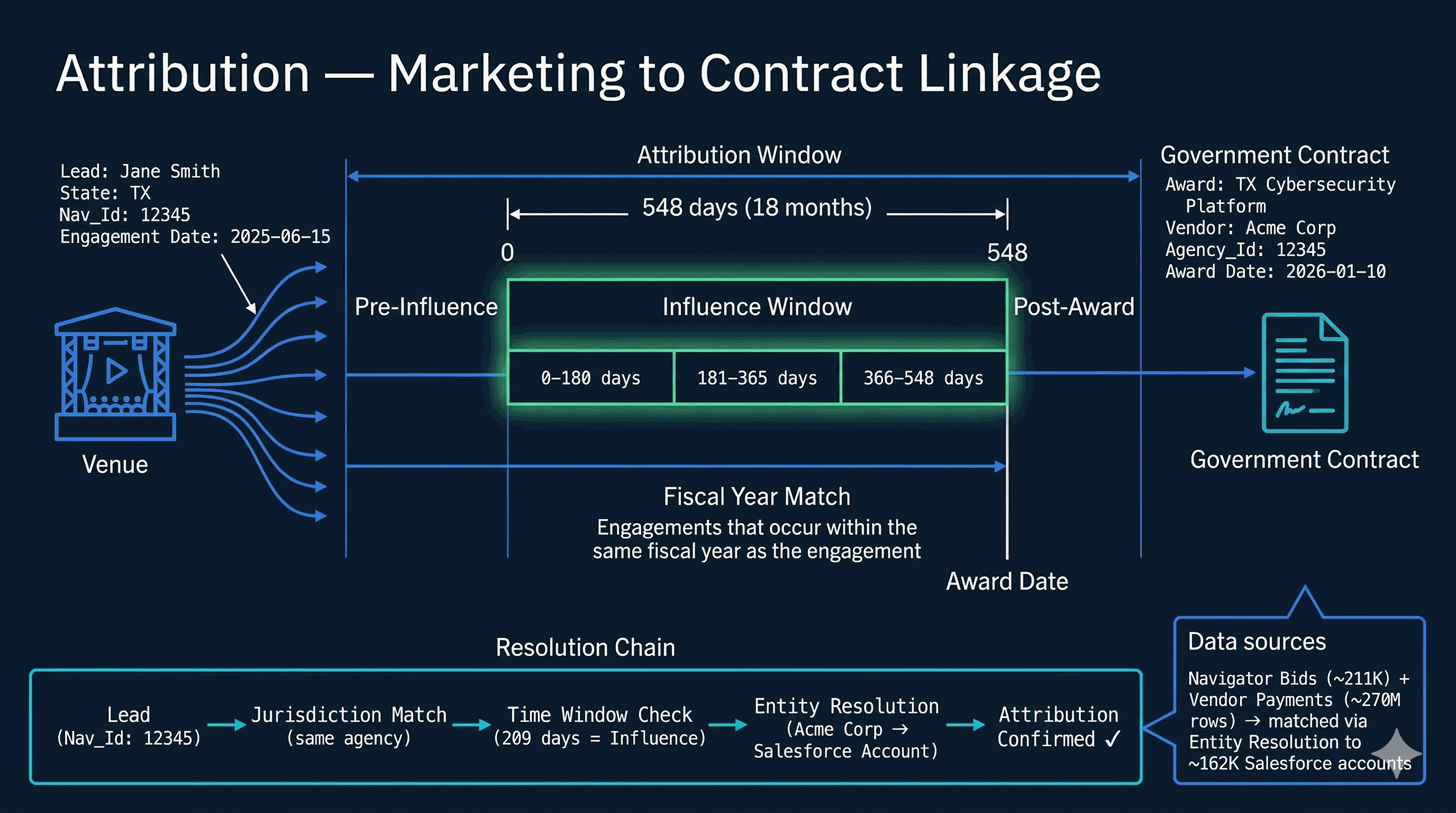
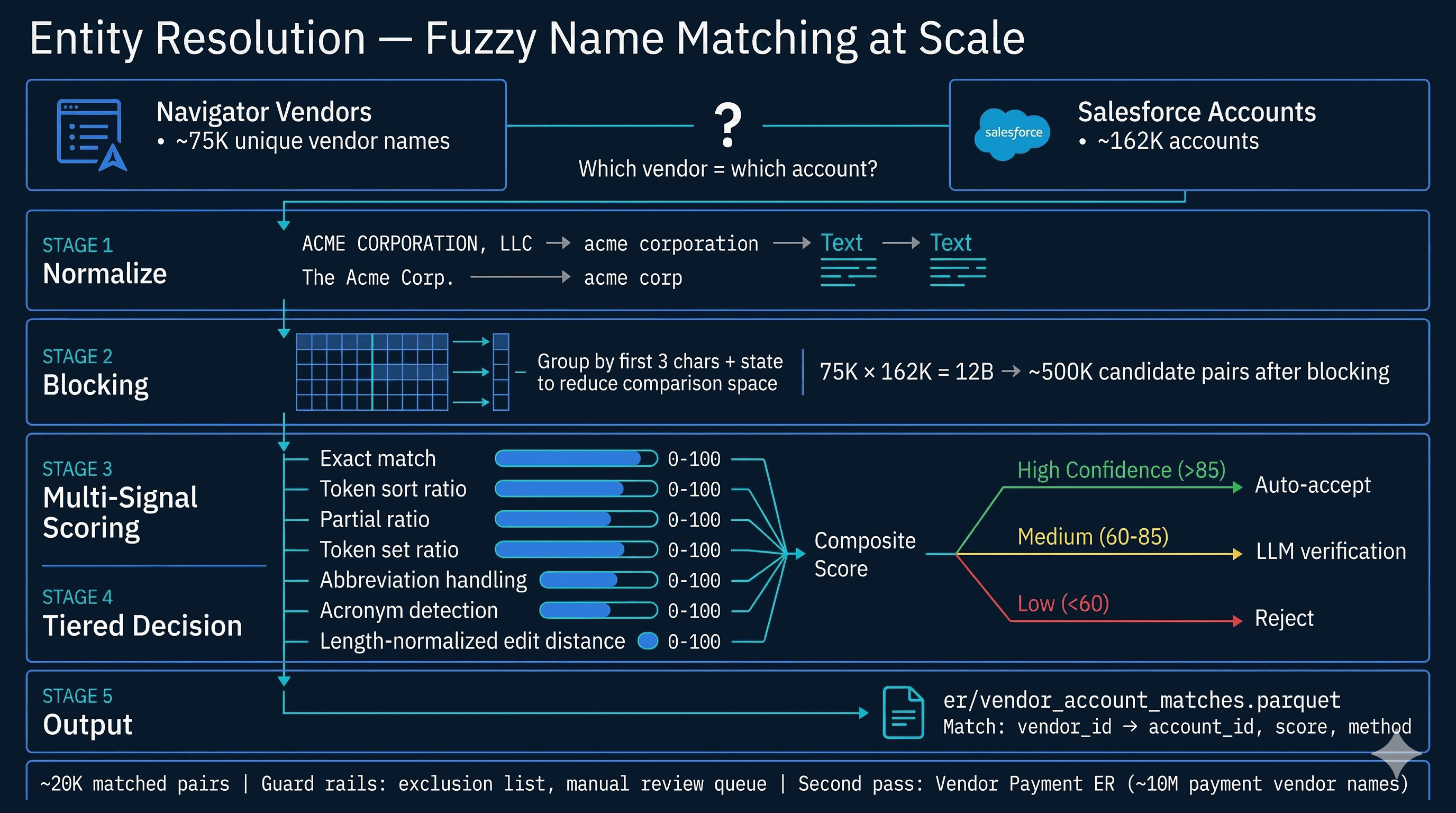
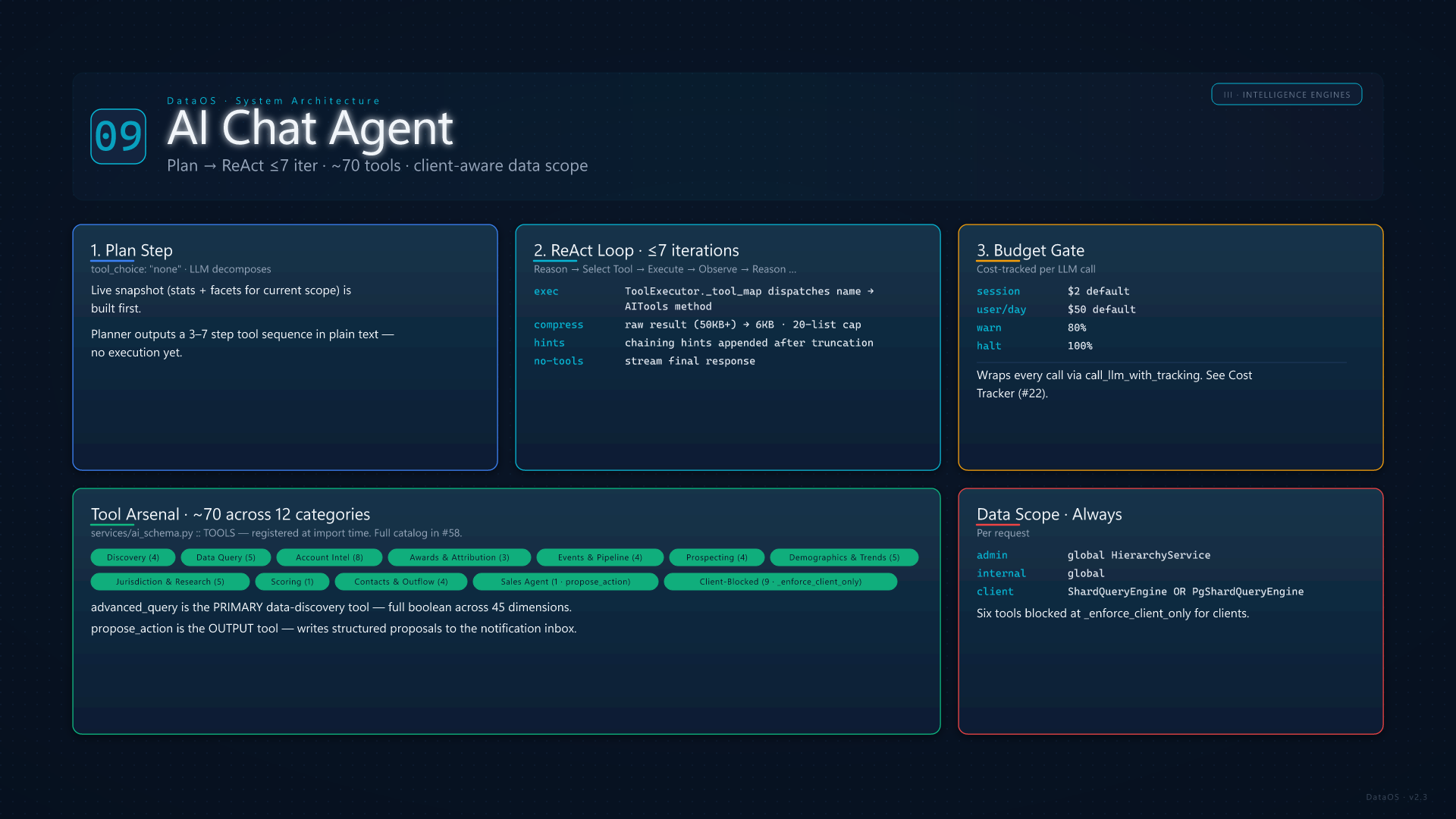
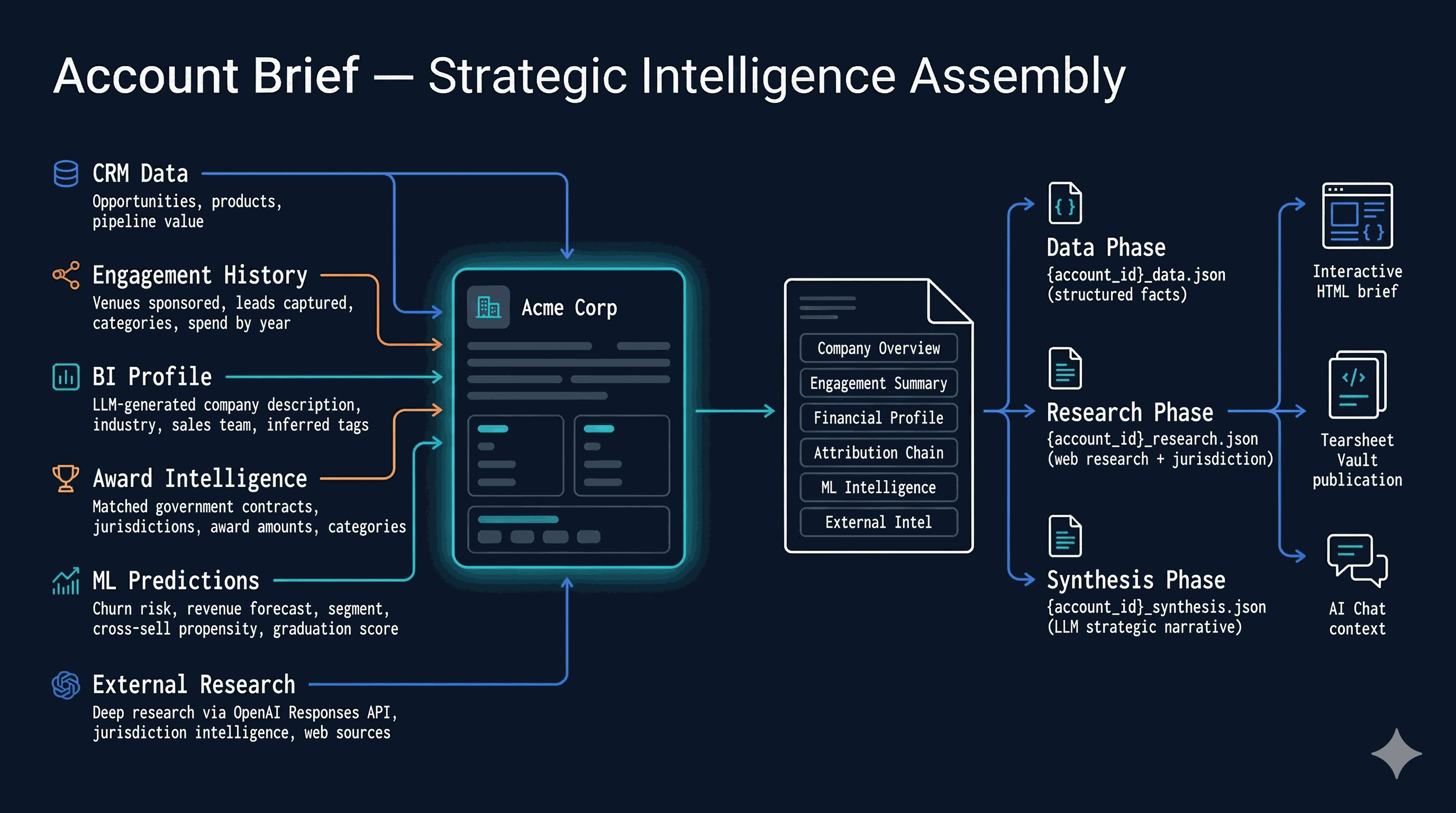
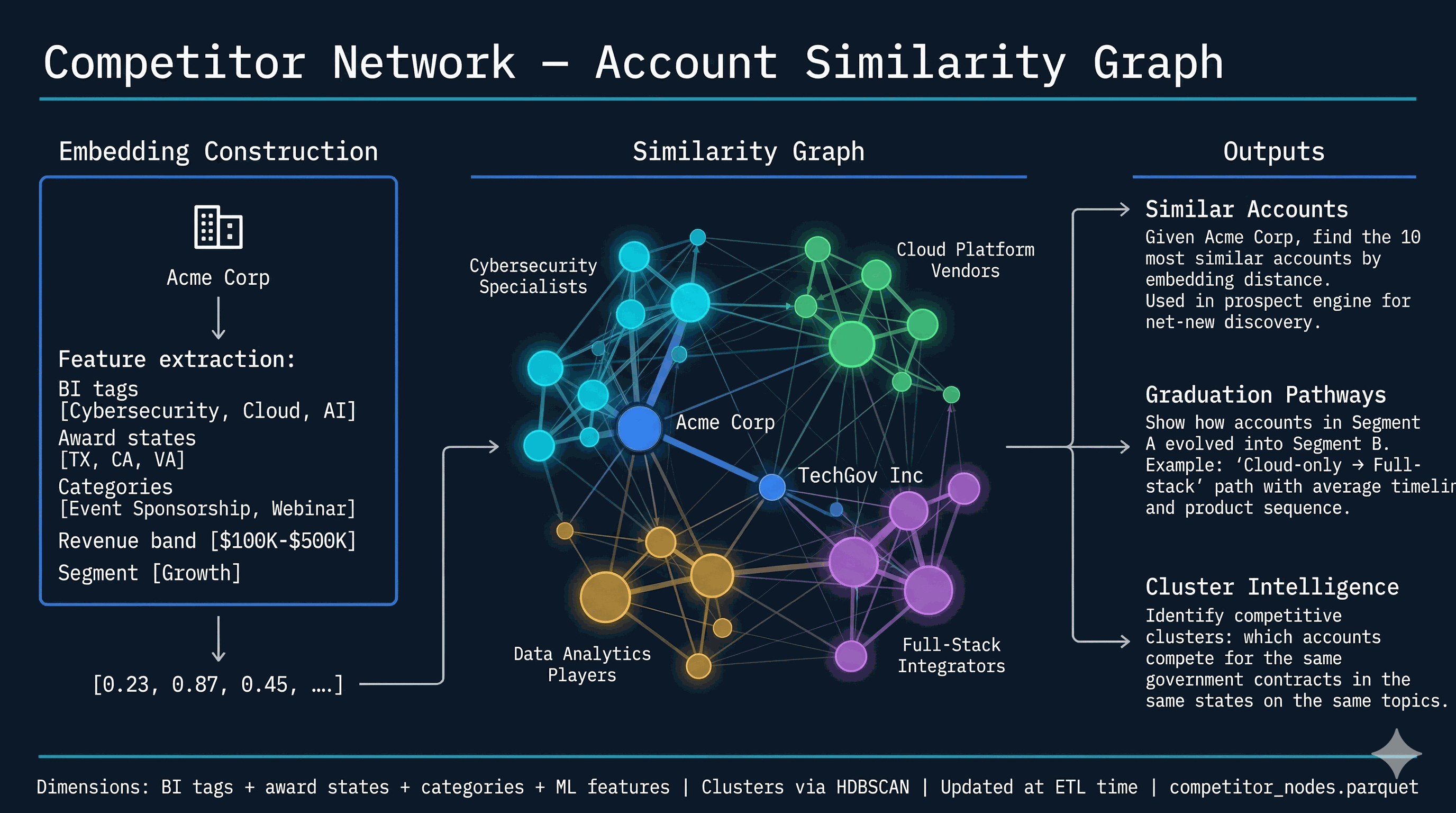
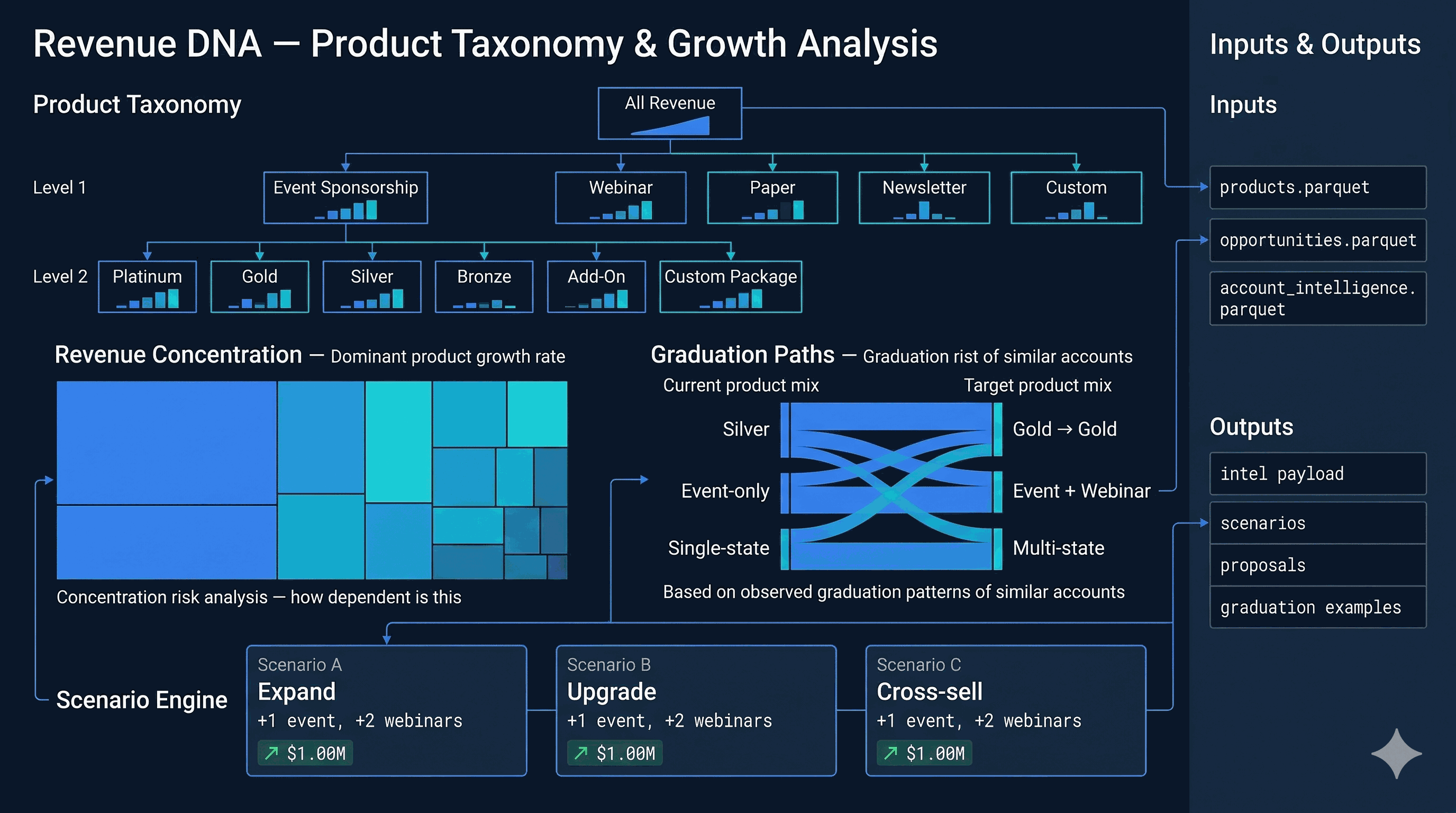
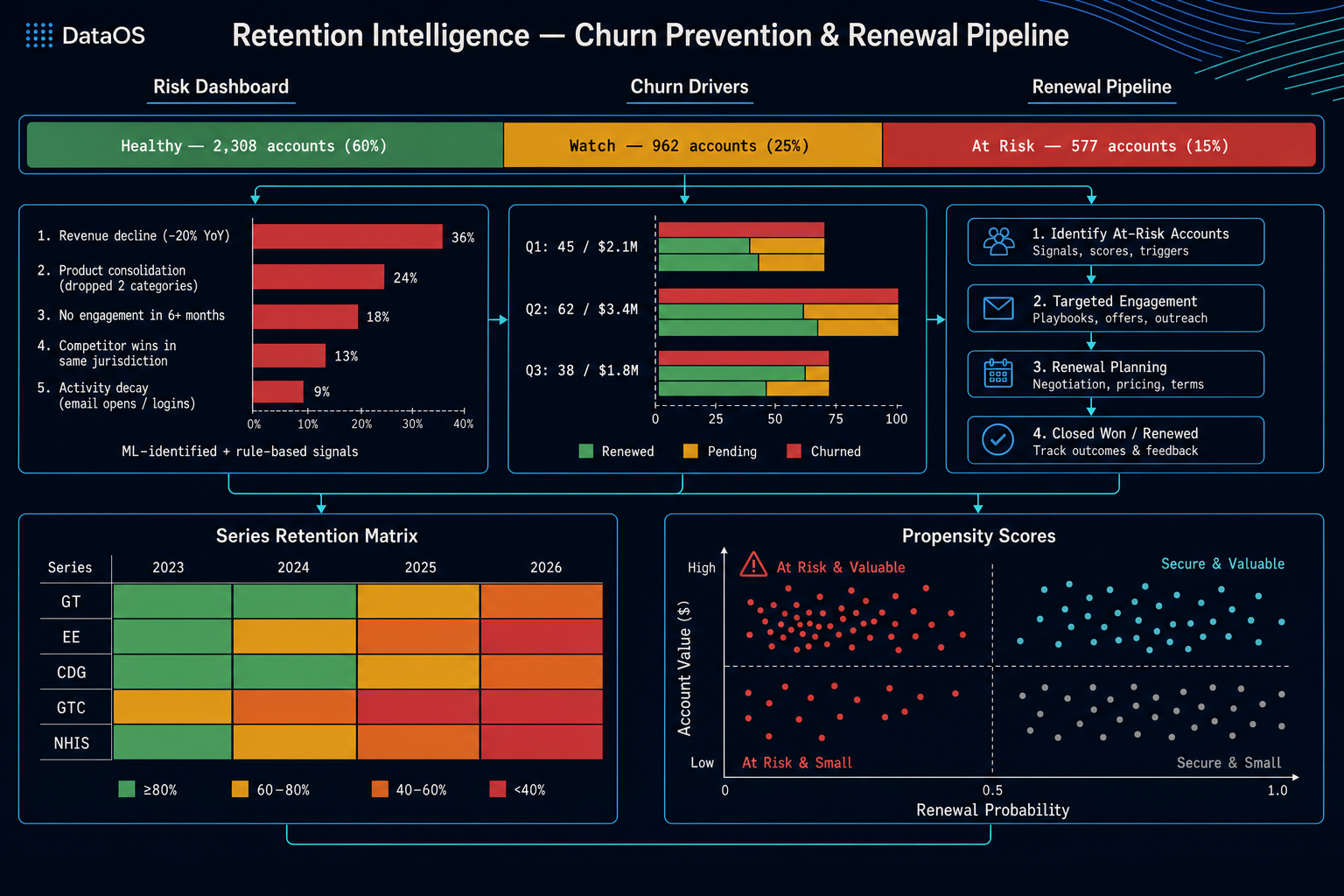
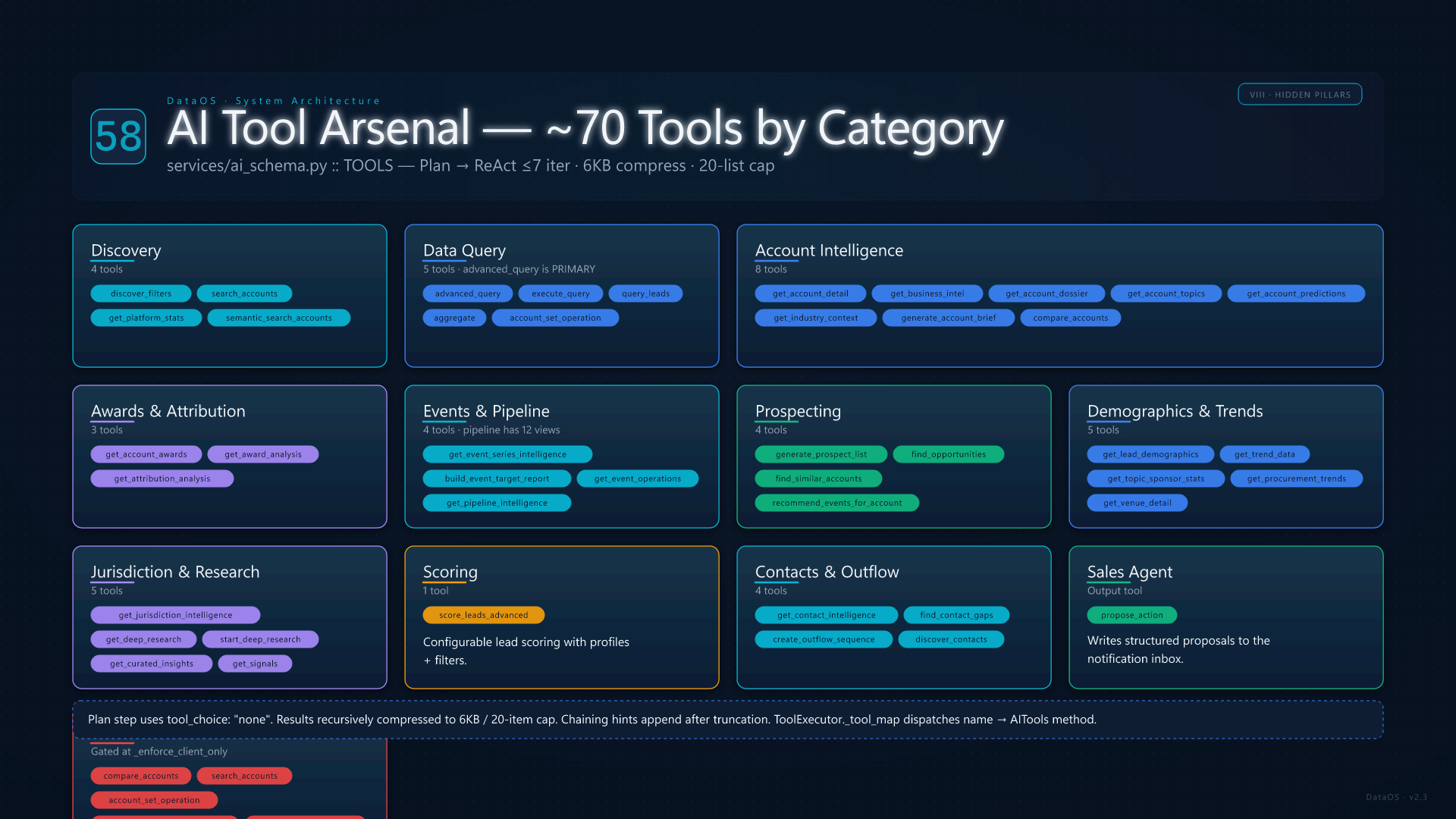
The TOOLS dict in services/ai_schema.py registers ~70 callable tools, each with a JSON schema, a description, and a return contract. Categories: Discovery — discover_filters, search_accounts, get_platform_stats, semantic_search_accounts. Data Query — advanced_query (the primary data-discovery tool, full boolean across 45 dimensions), execute_query, query_leads, aggregate, account_set_operation (intersect / subtract / union for gap analysis). Account Intelligence — get_account_detail, get_business_intel, get_account_dossier, get_account_topics, get_account_predictions, get_industry_context, generate_account_brief, compare_accounts. Awards & Attribution — get_account_awards, get_award_analysis, get_attribution_analysis.
Events & Pipeline — get_event_series_intelligence, build_event_target_report, get_event_operations, get_pipeline_intelligence (12 views: summary, teams, reps, accounts, stages, products, health, velocity, gaps, deals, opportunity, revenue). Prospecting — generate_prospect_list, find_opportunities, find_similar_accounts, recommend_events_for_account. Demographics & Trends — get_lead_demographics, get_trend_data, get_topic_sponsor_stats, get_procurement_trends, get_venue_detail. Intelligence — get_jurisdiction_intelligence (5 views), get_deep_research, start_deep_research, get_curated_insights, get_signals. Scoring — score_leads_advanced. Contacts & Outflow — get_contact_intelligence, find_contact_gaps, create_outflow_sequence, discover_contacts. Sales Agent action — propose_action (the output tool that writes structured proposals to the notification inbox). Six tools are admin-only and blocked at _enforce_client_only: compare_accounts, search_accounts, account_set_operation, plus the four intelligence-engine tools.